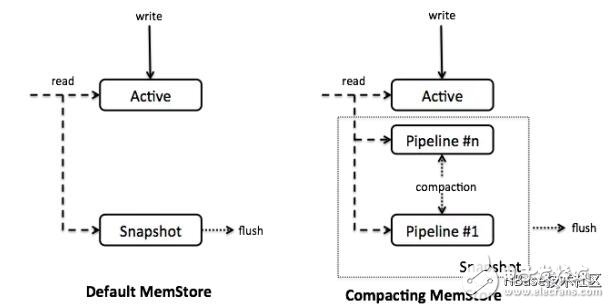
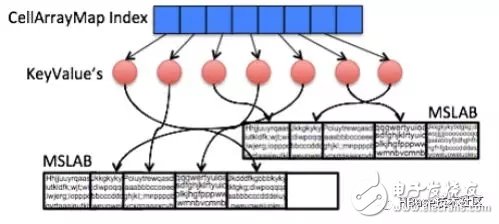
Today, people are increasingly demanding read and write speeds for HBase-based products. Ideally, people want HBase to be able to read and write memory data while maintaining reliable and persistent storage. For this reason, the Accordion algorithm was introduced in HBase 2.0. Hbase RegionServer is responsible for dividing data into multiple regions. The scalability of RegionServer's internal (vertical) performance is critical to the end-user experience and overall system utilization. The Accordion algorithm improves RegionServer scalability by increasing utilization of RAM. This allows more data to be stored in memory, thereby reducing the frequency of disk reads (ie, reducing the disk occupancy and write methods in HBase, more read and write RAM, and reducing IO access to disks). Prior to HBase 2.0, these indicators could not be satisfied at the same time, and they were mutually restrictive. After the introduction of Accordion, this situation was improved. The Accordion algorithm is derived from the HBase core architecture LSM algorithm. In HBase Region, data is mapped as searchable according to the key-value form. The new data put in and some topmost data are stored in memory (MemStore), and the rest are unchanged HDFS files. That is HFile. When the MemStore is full, the data is flushed to the hard disk and a new HFile file is generated. HBase adopts multi-version concurrency control. MemStore stores all modified data as independent versions. Multiple versions of a piece of data may be stored in MemStore and HFile at the same time. When reading a multi-version data, the HBase file in BlockCache is scanned according to the key to obtain the latest version data. In order to reduce the frequency of access to the disk, HFiles merge in the background (ie, compression process, delete redundant cells, create a larger file). LSM improves write performance by converting random reads and writes to sequential reads and writes. The previous design did not use compressed memory data. The main reason was that at the beginning of the LSM tree design, RAM was a very scarce resource, so the capacity of the MemStore was very small. As the hardware continues to increase, the entire MemStore managed by the RegionServer may be several gigabytes, which leaves a lot of room for HBase optimization. The Accordion algorithm re-applies the LSM to the MemStore so that redundancy and other overhead can be eliminated when the data is still in RAM. This reduces the frequency of flushing to HDFS, which reduces write amplification and disk usage. As the number of flushes decreases, the frequency at which MemStore writes to the disk decreases, which in turn increases HBase write performance. Fewer data on the disk also means less stress on the block cache, improving read response time. Finally, reducing writes to the disk also means that the number of compressions in the background is reduced, that is, the read and write cycles will be shortened. All in all, the effect of the memory compression algorithm can be seen as a catalyst that makes the entire system run faster. Accordion currently offers two levels of memory compression: the basic level and the eager level. The former applies to the optimization of all data updates, and the latter is useful for high data stream applications such as production-consumer queues, shopping carts, shared counters, and the like. All of these use cases will frequently update rowkey to generate multiple redundant versions of data. In these cases, the Accordion algorithm will have its value. On the other hand, eager-level compression optimizations may increase computational overhead (more memory copies and garbage collection), which may affect the response time of data writes. If MemStore uses the on- heap MemStore-local allocation buffer (MSLAB), this can lead to increased overhead. It is not recommended to use this configuration with eager-level compression. Memory compression can be configured at the global and column family level. Currently supports three levels of configuration: none (traditional), basic, and eager. By default, all tables are basic memory compression. This configuration can be modified in hbase-site.xml as follows: Property name name hbase.hregion.compacTIng.memstore.type /name value value none|basic|eager /value /property Each column family can also be individually configured in the HBase shell as follows: Create '"tablename"', {NAME = "'cfname'', IN_MEMORY_COMPACTION ="' "NONE|BASIC|EAGER"' } HBase was thoroughly tested using YCSB (Yahoo Cloud Service Benchmark). The data set size used in the experiment was 100-200 GB. The result shows that the Accordion algorithm has significantly improved HBase performance. Heavy-tailed (Zipf) distribution: In test load China, rowkey follows the Zipf distribution that appears in most real life scenarios. In this case, when 100% of the operations were write operations, Accordion achieved a 30% reduction in write amplification, a 20% increase in write throughput, and a 22% reduction in GC. When 50% of operations are read, the tail read latency is reduced by 12%. Evenly distributed: Rowkey is evenly distributed in the second test. When 100% of the operations were write operations, Accordion's write magnification decreased by 25%, write throughput increased by 50%, and GC decreased by 36%. Tail read latency is not affected (due to no localization). How Accordion Works High Level Design: Accordion introduced MemStore's internal compression (CompacTIngMemStore) implementation. Compared to the default MemStore, Accordion stores all data in a single data structure and manages it with segments. The latest segment, called acTIve segment, is mutable and can be used to receive Put operations. If the active segment reaches the overflow condition (32MB by default, 25% of MemStore size), they will be moved to the in-memory pipeline. , and set to immutable segment, we call this process in-memory flush. The Get operation fetches data by scanning these segments and HFiles (the latter operation is accessed through the block cache, as is usual access to HBase). CompactingMemStore may merge multiple immutable segments in the background from time to time to form a larger segment. Therefore, the pipeline is "breathing" (expansion and contraction), similar to the accordion bellows, so we have also translated Accordion into the accordion. When RegionServer flushes one or more MemStores to disk to free up memory, it will flush the segments in the CompactingMemStore that have been piped into the disk. The basic principle is to extend the MemStore's effective management of the memory life cycle to reduce overall I/O. When flush occurs, all segment segments in the pipeline will be moved out of a composite snapshot, forming a new HFile by merging and streaming. Figure 1 shows the structure of the CompactingMemStore and the traditional design. Figure 1. CompactingMemStore and DefaultMemStore Similar to the default MemStore, the CompactingMemStore maintains an index on the cell store so that it can be quickly searched by key. The difference between the two is that the MemStore index implementation manages a large number of small objects through the Java skiplist (ConcurrentSkipListMap - a dynamic but extravagant data structure). CompactingMemStore implements an efficient and space-saving flat layout above the immutable segment index. This optimization can help reduce the RAM overhead for all compression strategies and can even make the data almost redundant. When a Segment is added to the pipeline, CompactingMemStore serializes its index into an ordered array called CellArrayMap, which can quickly perform binary searches. CellArrayMap supports both direct allocation of units from within the Java heap and support for custom allocations (inside or out of heap) by MSLAB. Differences are abstracted out by the KeyValue object referenced by the index (Figure 2). The CellArrayMap itself is always allocated on the heap. Figure 2. Immutable Segments with Flat CellArray Map Index and MSLAB Unit Storage The in-memory compression algorithm maintains a single flattened index on the Segment in the pipeline. This design saves storage space, especially when the data items are very small, so that data can be flushed to disk in a timely manner. A single index allows search operations to occur in a single space, thus reducing tail read latency. When an active segment is flushed to memory, it is queued to the compression pipeline and an asynchronous merge scheduling task is immediately triggered. The scheduled task will simultaneously scan all segments in the pipeline (similar to on-disk compression) and merge their indexes into one. The difference between basic and eager compression strategies is reflected in the way they handle unit data. Basic compression does not eliminate redundant data versions to avoid physical copying, it merely rearranges references to KeyValue objects. Eager compression, on the other hand, filters out redundant data, but this comes at the cost of extra calculations and data migration. For example, in the MSLAB memory, the surviving unit is copied into the newly created MSLAB. Future compression may automatically select between basic compression and eager compression. For example, the algorithm may try eager compression over a period of time and schedule the next compression based on the value passed (eg, the percentage of data being deleted). This approach can ease system administrators' a priori decisions and adapt to changing access patterns. Displacement sensor, also known as linear sensor, is a linear device belonging to metal induction. The function of the sensor is to convert various measured physical quantities into electricity. In the production process, the measurement of displacement is generally divided into measuring the physical size and mechanical displacement. According to the different forms of the measured variable, the displacement sensor can be divided into two types: analog and digital. The analog type can be divided into two types: physical property type and structural type. Commonly used displacement sensors are mostly analog structures, including potentiometer-type displacement sensors, inductive displacement sensors, self-aligning machines, capacitive displacement sensors, eddy current displacement sensors, Hall-type displacement sensors, etc. An important advantage of the digital displacement sensor is that it is convenient to send the signal directly into the computer system. This kind of sensor is developing rapidly, and its application is increasingly widespread. Magnetic Scale Sensor,Magnetic Length Scale,Magnetic Scale Device,Magnetic Scale Measurements Changchun Guangxing Sensing Technology Co.LTD , https://www.gx-encoder.com